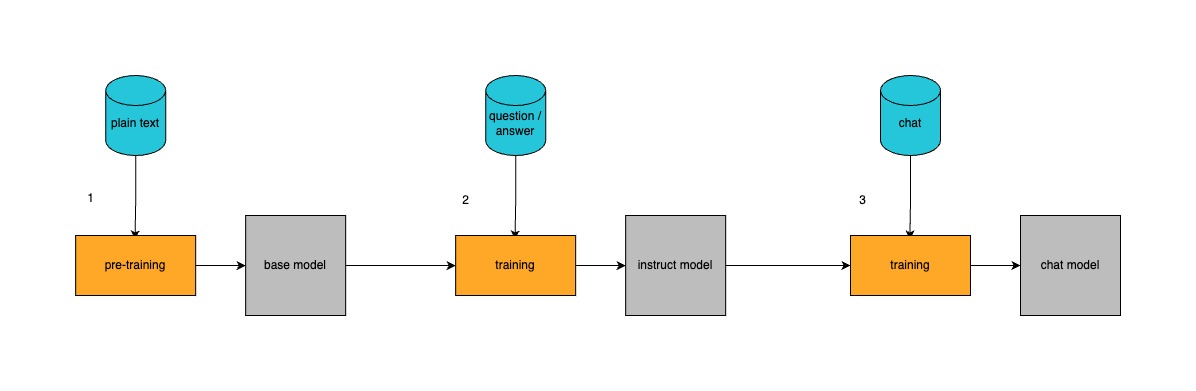
Let’s recap how LLMs are created, it will help to better understand the whole fine-tuning pipeline.
The training lifecycle typically involves three stages:
- Pre-training
The model is initially trained on vast amounts of unstructured text data using a next-token prediction objective. This stage results in a base model that captures general language patterns but might not follow specific instructions. - Supervised Fine Tuning (SFT)
In this stage, the base model is trained on pairs of questions (or instructions) and answers. The goal is to adjust the model so it not only continues text but also understands and follows specific commands. During SFT, the model is exposed to curated datasets that help it answer questions correctly and align with the intended behavior. - Preference Alignment
Many production models go through an additional stage where human feedback is used to fine tune the model’s behavior further, often resulting in chat-optimized models.
Fine Tuning Libraries
There are several robust libraries available to help you fine tune LLMs efficiently. Some popular options include:
- TRL (Transformers Reinforcement Learning) by Hugging Face
Built on top of the Transformers library, TRL is user-friendly and integrates well with existing Hugging Face tools.
See - Unsloth
Built on top of PyTorch and leverages Triton kernels to optimize backpropagation and reduce memory usage, making the fine-tuning process faster and more efficient. - Axolotl
A versatile library that uses YAML configuration files for customization and ease of setup. - LLaMA Factory
Known for its graphical user interface that simplifies the process, making fine tuning more accessible.
Each of these libraries has its strengths, and your choice might depend on factors such as the model architecture, available computational resources, and your familiarity with the framework.
Creating an SFT Dataset
The quality of your SFT dataset is crucial to successful fine tuning. Here are some key points to consider when creating your dataset:
- Data Sources
Start with open source datasets if available. You can combine multiple datasets to ensure a diverse range of topics and writing styles. - Data Characteristics
- Accuracy: Ensure that the outputs are factually correct and free of typos.
- Diversity: Include a wide variety of topics and styles to cover as many scenarios as possible.
- Complexity: Incorporate complex tasks that require the model to perform reasoning (for example, chain-of-thought responses).
- Data Preparation Techniques
- Synthetic Data Generation: Use pre-trained “frontier” models to generate synthetic data, especially if human-curated data is limited.
- Data Deduplication: Remove exact or fuzzy duplicates to prevent the model from overfitting on repeated content.
- Quality Filtering: Apply rule-based filters or more sophisticated techniques (e.g., using reward models or another language model as a judge) to discard low-quality samples.
- Data Exploration: Utilize tools for clustering and visualization (such as topic clustering algorithms) to understand the dataset and identify areas for improvement.
You can also see The FAA Balloon Flying Handbook Dataset
SFT Techniques
When fine tuning, there are several techniques to consider based on your requirements and computational resources:
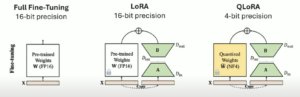
- Full Fine Tuning
Train the entire model on the instruction dataset. While this can yield the best performance, it is often the most resource-intensive approach. - Parameter-Efficient Fine Tuning (PEFT)
Instead of updating all the weights of the model, freeze the majority of the pre-trained weights and add smaller trainable components called adapters.- Low-Rank Adaptation (LoRA): This method introduces low-rank matrices (adapters) to targeted layers. It reduces training time and resource usage while still achieving competitive performance.
- Quantized Fine Tuning
Fine tune models that have been quantized (e.g., to 4-bit precision) to reduce VRAM usage. Note that while quantization can save resources, it might come with a trade-off in performance.
Each technique has its pros and cons. For instance, full fine tuning might be ideal for achieving the highest performance, but adapter-based methods like LoRA offer a great balance between efficiency and effectiveness.
See Teaching an LLM How to Fly a Hot Air Balloon as example of how to use TRL.
Key Hyperparameters
Fine tuning requires careful tuning of several hyperparameters. While the optimal values can depend on the model and the dataset, the following are generally critical:
- Learning Rate:
Typically, you want to start with the highest rate that does not cause the loss to explode. A few experiments are usually necessary to pinpoint the ideal value. - Number of Epochs:
Depending on the size of your dataset, adjust the number of epochs to ensure sufficient learning without overfitting. - Sequence Length:
This is a balance—longer sequences provide more context but consume more memory. Often, the sequence length used for fine tuning is shorter than that of the pre-training stage. - Batch Size:
Maximize the batch size to utilize your GPU effectively, keeping in mind the VRAM limitations. - Adapter-Specific Parameters (if using PEFT):
For example, the rank in LoRA can be adjusted to balance performance improvements with resource constraints.
I wrote a full blog post about the topic, see Understanding Key Hyperparameters When Fine-Tuning an LLM
Conclusion
Fine tuning LLMs is a powerful technique to adapt a general-purpose base model to your specific needs. By understanding the training lifecycle, selecting the right fine tuning libraries, meticulously creating your SFT dataset, and carefully choosing your fine tuning techniques and hyperparameters, you can significantly improve model performance. Whether you’re working on a chatbot, a question-answering system, or any other language-based application, these principles provide a solid starting point.
And if you need help, feel free to reach out!
Happy fine tuning!