Keeping your data in-house
In today’s data-driven world, companies are increasingly concerned about sensitive data leaving their boundaries. Deploying your own Large Language Model (LLM) isn’t just about harnessing the latest AI—it’s also about ensuring your data remains secure and compliant. Relying on third-party APIs can expose your intellectual property and customer data. By serving your own LLM, you maintain full control over both performance and privacy.
Why single-user approaches fail at scale
Solutions like OLAMA are designed for single-user scenarios. While they might perform adequately for one-off requests, they simply can’t handle the load when multiple users interact concurrently. In such deployments, generation requests stack one after another—leading to cascading timeouts on the second, third, and subsequent concurrent requests.
The blueprint for scalable LLM deployment
To truly serve an LLM at scale, you need a robust text generation inference server capable of handling high concurrency. Here’s what it takes:
-
Dynamic and Continuous Batching:
Combining requests into batches dynamically lets your system process multiple generation requests concurrently without waiting for each one to finish individually. -
Asynchronous Scheduling and Streaming:
With asynchronous task management, the server can schedule token generation and stream responses without blocking subsequent requests. This helps maintain low latency even under heavy load. -
Efficient Memory Management and Parallelism:
Advanced memory management techniques ensure that multiple GPUs can be utilized simultaneously, distributing the computational load evenly. -
KV Cache Reuse:
Reusing key-value caches across generation steps accelerates token production by avoiding redundant computation.
These four pillars are not just theoretical; they form the foundation of performance-optimized inference servers like Hugging Face’s Text Generation Inference (TGI) and alternatives like vLLM.
Benchmarking in Action: Deep Dive into the TGI Benchmark Interface
The TGI benchmark tool is divided into four key areas:
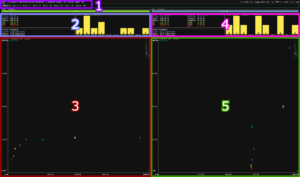
1 – Batch Selector: This component lets you choose the batch size—that is, the number of concurrent requests—to simulate different levels of user load.
2 – Pre-Fill Metrics and Histogram: This area visualizes the performance during the “pre-fill” phase, where the entire prompt is processed in a single forward pass. Here, you’ll see detailed stats and histograms that show how quickly the server can process the initial prompt.
3 – Pre-Fill Throughput over Latency Scatter Plot: This scatter maps out the trade-off between throughput (how many tokens are generated per second) and latency (how long each token takes to process). The ideal performance is indicated by low latency with high throughput—points that cluster in the top left of the chart.
4 – Decoding Metrics and Histogram: This section focuses on the decoding phase, where each new token is generated sequentially after the pre-fill.
5 – Decoding Throughput over Latency Scatter Plot: It provides insight into how the system handles ongoing token generation, crucial for understanding the end-user experience during longer responses. X-axis is latency (small is good). Y-axis is throughput (large is good). An “ideal” point would be in the top left corner (low latency and high throughput) (same concept applies to area 3)
Connecting to Our Benchmark Scenario
For our benchmark, we are using an RTX 6000 ADA using Zephyr 7B model running on Runpod.
The benchmark I conducted was by testing 8,16,32,64,128 and 256 concurrent users
By looking at all the batches and in particular at area 5 Decoding Throughput over Latency (the most important), we can clearly see a soft spot where 64 concurrent users will experience a decent token generation
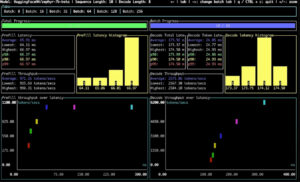
In just a few clicks we have an understanding of what will happen to our users and the experience they will get: 32 concurrent users will experience a speed response from the LLM fairly similar to the one you have on chatGPT, 64 user will experience something a bit slower but fairly acceptable.
Now your role is to understand, given the total number of users in your organizations, how many of them are using the tool.
This is a whole different story, I’ve done such study in depth in the past, and they require data, lots of data 🙂
Conclusion: The Journey Has Just Begun
This post barely scratches the surface of text generation inference deployment. If you’re ready to dive deeper, I can help with detailed analyses, forecasts, and hands-on deployment strategies drawn from my extensive experience in this space. Reach out for assistance and let’s ensure your LLM serves your users flawlessly—while keeping your data safely within your company’s walls.