DeepSeek-OCR: Beyond Traditional OCR
That is just the case to say: “a picture is worth a thousand words” - but what if a picture could be worth exactly 1,000 text tokens with 97% accuracy? DeepSeek-AI’s latest release, DeepSeek-OCR, isn’t just another OCR model. It’s a paradigm shift in how we think about AI memory, long-context processing, and the fundamental role of vision in language models.
The core breakthrough: DeepSeek-OCR achieves 10x compression by using 100 vision tokens to represent 1,000 text tokens with 97% decoding precision. At 20x compression (50 vision tokens), it still maintains ~60% accuracy. This isn’t about reading documents better - it’s about fundamentally rethinking how LLMs handle information.
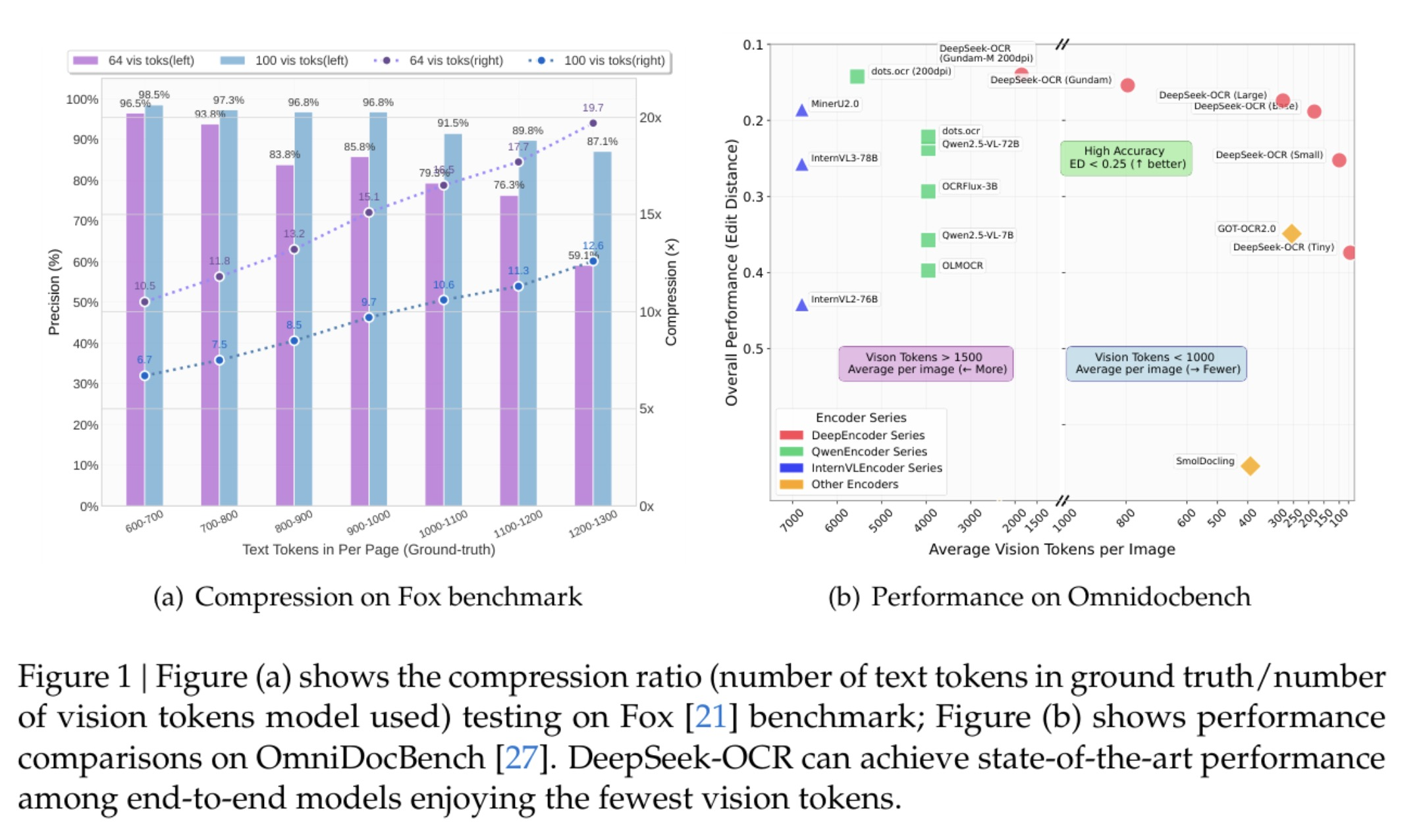 Compression ratios on Fox benchmark and performance on OmniDocBench
Compression ratios on Fox benchmark and performance on OmniDocBench
The Real Problem: LLM Context Windows
Large Language Models face a critical computational challenge when processing long contexts. The traditional approach requires roughly one token per word, meaning a million-token context window translates to massive computational overhead. Extending this to 10 million or even 20 million tokens becomes prohibitively expensive.
Why Current Approaches Fall Short
As detailed in the information theory perspective, text tokens are inherently constrained by symbolic entropy. When we tokenize text like “Caleb writes code” into token IDs [100, 59, 67], we’ve hit the compression ceiling - you can’t compress these symbolic representations further without losing meaning. This symbolic entropy creates an upper bound on information density.
Current vision encoders in VLMs suffer from three critical deficiencies:
- Too many vision tokens - making compression impossible
- Excessive memory requirements - limiting practical deployment
- Poor high-resolution handling - losing critical details
The Solution: Context Optical Compression
DeepSeek-OCR introduces contexts optical compression - using vision as a compression algorithm for text. Instead of converting images to tokens, they flip the paradigm: store text IN images, then decode those compressed visual representations.
Key Innovation: DeepEncoder Architecture
The secret sauce is the DeepEncoder, a two-stage architecture that maintains high-resolution perception while achieving dramatic token reduction:
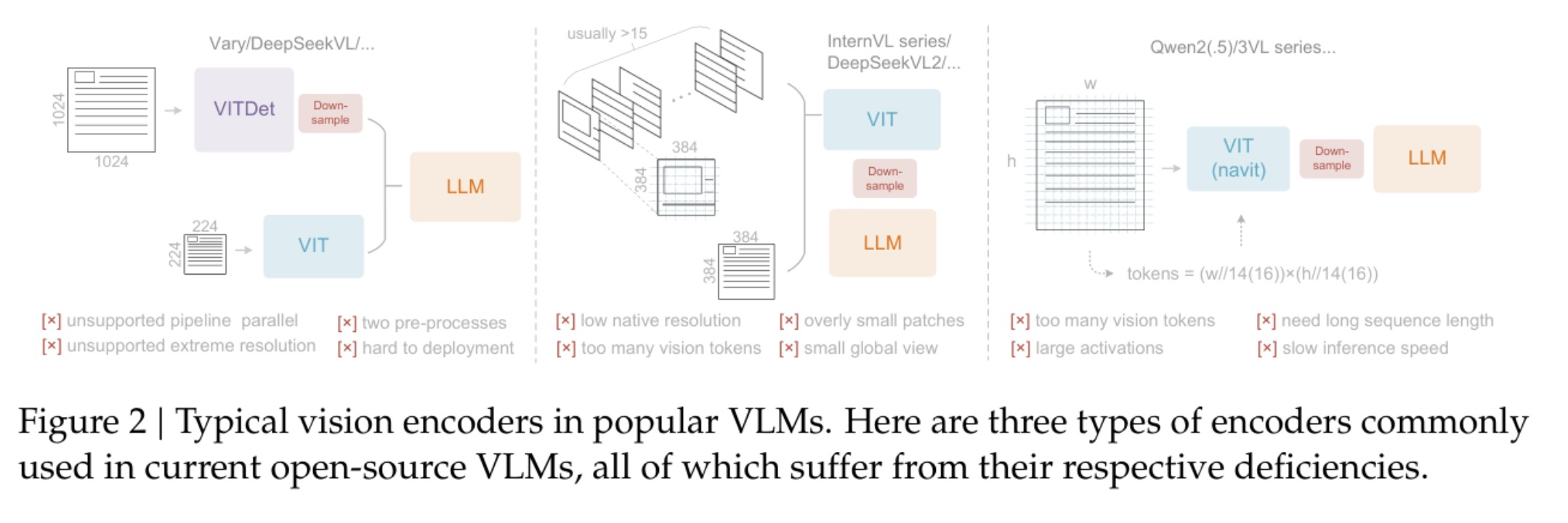 Typical vision encoders in popular VLMs - showing their deficienciesh
Typical vision encoders in popular VLMs - showing their deficienciesh
Stage 1: High-Resolution Attention
- Uses SAM (Segment Anything Model) - only ~80M parameters
- Processes images at high resolution to capture fine details
- Compresses via CNN by 16x before stage 2
Stage 2: Global Attention
- CLIP model processes compressed representations
- Uses global attention to understand relationships
- Outputs compact, information-dense vision tokens
This multi-stage approach extracts information efficiently rather than naively applying attention to everything and generating excessive tokens.
Multi-Resolution Modes
DeepSeek-OCR supports adaptive resolution modes:
- Tiny mode: 64 tokens (512×512)
- Small mode: 100 tokens (640×640)
- Base mode: 256 tokens (1024×1024)
- Large mode: 400 tokens (1280×1280)
- Gundam mode: ~1800 tokens (dynamic: n×640×640 + 1×1024×1024)
Real-world comparison: Traditional approaches need 6,000+ tokens to represent a document. DeepSeek-OCR achieves better performance with under 800 vision tokens - and outperforms GOT-OCR2.0 (256 tokens/page) and MinerU2.0 (6000+ tokens/page) by up to 60x fewer tokens on OmniDocBench.
The Tokenizer Problem: Karpathy’s Perspective
The pain points of text tokens are well-articulated by Andrej Karpathy in a recent post about DeepSeek-OCR:
“Delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It ‘imports’ all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an… actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.”
Karpathy’s analysis highlights a crucial insight: maybe all inputs to LLMs should be images. Even pure text could be rendered and fed as images, offering:
- More information compression → shorter context windows, higher efficiency
- Significantly more general information stream → not just text, but bold text, colored text, arbitrary images
- Bidirectional attention by default → not constrained to autoregressive processing
- No tokenizer complexity → eliminating Unicode ugliness and security risks
The latent representation of an image can be far more information-dense than text, where structure is constrained by tokens as the lowest common denominator.
Architecture Deep Dive
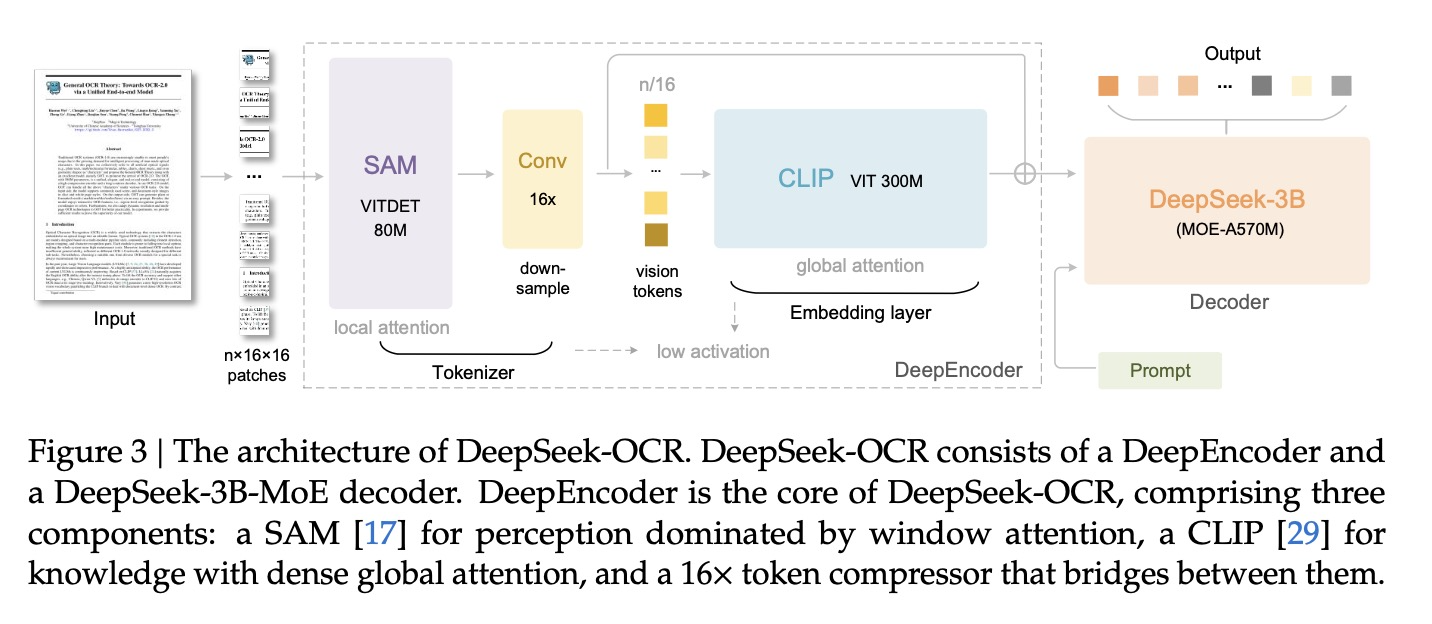
DeepEncoder Implementation
![DeepEncoder Architecture - placeholder for paper diagram] [TODO: Reference specific architecture diagram from paper]
 DeepEncoder Architecture
DeepEncoder Architecture
The DeepEncoder serially connects:
- Local attention encoder (SAM) - processes high-resolution input
- 16x convolutional compressor - reduces activation memory
- Global attention encoder (CLIP) - understands relationships
This design ensures the window attention component processes many vision tokens, while the dense global attention component receives fewer tokens, achieving effective memory and token compression.
Decoder: DeepSeek-3B-MoE
The decoder is a lightweight DeepSeek-3B Mixture-of-Experts model with only 570 million active parameters. It generates structured Markdown output with:
- Multi-language support (100+ languages)
- Mathematical formulas (LaTeX)
- Tables and structured data
- Charts and diagrams
Training Data and Performance
The model was trained on massive, diverse datasets:
- 30+ million PDF pages across 100 languages
- 10 million natural scene OCR samples
- 10 million charts and diagrams
- 5 million chemical formulas
- 1 million geometry problems
Benchmark Results
On the Fox benchmark, DeepSeek-OCR maintains:
- 97% accuracy at 10x compression
- ~60% accuracy at 20x compression
Production throughput: Over 200,000 pages/day on a single NVIDIA A100 GPU, enabling scalable LLM training data generation.
Real-World Applications: Beyond Theory
Brian Roemmele’s Microfiche Project
Brian Roemmele demonstrated DeepSeek-OCR’s practical capabilities by scanning entire microfiche sheets at 4am and achieving 100% data retention in seconds. His work with 1870-1970 offline digitized data showcases the model’s ability to:
 Brian Roemmele’s microfiche scanning setup with DeepSeek-OCR
Brian Roemmele’s microfiche scanning setup with DeepSeek-OCR
- Scan complex microfiche grids with hundreds of cells
- Understand text AND complex drawings with full context
- Process historical documents with perfect fidelity
- Transform offline data curation workflows
As Brian notes in his analysis:
“An entire encyclopedia compressed into a single, high-resolution image! DeepSeek-OCR crushes long documents into vision tokens with a staggering 97% decoding precision at a 10x compression ratio! That’s thousands of textual tokens distilled into a mere 100 vision tokens per page, outmuscling GOT-OCR2.0 (256 tokens) and MinerU2.0 (6,000 tokens) by up to 60x fewer tokens.”
Future Implications
The Theoretical Promise
While currently proven for OCR tasks, the implications extend far beyond document processing. The theoretical possibility: using 500,000 vision tokens to replace 5 million text tokens for general LLM contexts.
Imagine architectures where:
- Recent conversations remain as high-resolution text tokens
- Older context gets rendered as compressed images
- Both remain accessible in the context window for in-context learning
- Effective context windows reach 10-20 million text-token equivalents
Paradigm Shift Questions
This research raises fundamental questions:
- Are we moving toward models that think in pictures rather than words?
- How will prompt engineering evolve with image-based inputs?
- What happens to RAG and context management companies built around text tokens?
- Should vision become the universal input modality for LLMs?
As Karpathy observes:
“OCR is just one of many useful vision → text tasks. And text → text tasks can be made to be vision → text tasks. Not vice versa.”
Technical Specifications
Model Components:
- DeepEncoder: SAM + CNN (16x compression) + CLIP
- Decoder: DeepSeek-3B-MoE (570M active params)
- Context Window: 8,192 tokens max model length
- Vision Token Range: 64 to ~1800 (mode-dependent)
Supported Input:
- Documents (PDFs, images)
- Natural scenes with text
- Scientific diagrams and equations
- Charts and graphs
- Chemical formulas
- Geometric figures
Output Format:
- Structured Markdown
- LaTeX for mathematical content
- Multi-language support (100+ languages)
Part 2: Deploying DeepSeek-OCR – A Practical Guide
I’ve created a production-ready deployment repository with everything you need to run DeepSeek-OCR:
🔗 DeepSeek-OCR Deployment Repository
What’s Included:
1. Ready-to-Use Docker Image
- Pre-built image on Docker Hub:
gsantopaolo/deepseek-ocr:latest - vLLM-optimized with OpenAI-compatible API
- CUDA 12.1 with cuDNN support for GPU acceleration
2. RunPod Cloud Deployment
- One-click deployment template: Deploy on RunPod
- 5-minute setup from template to running API
- Cost-effective: ~$0.69/hour (RTX 4090) to ~$1.89/hour (A100)
3. Comprehensive Testing Suite
- Complete test scripts with real-world document examples
- Performance benchmarks and validation tools
Quick Start Options:
Option A: Deploy on RunPod (No Local GPU Required - Recommended)
Use my [RunPOd Template](RunPod. By clicking the link above you just need to decide which GPU server to use, scroll down and click deploy. Once deployed (it will take a wile since the live container will pull the model from HuggingFace) copy the connection link and pass it to test.py
1
python test.py --base-url http://your-runpod-instance:8000 --output results.md
Option B: Pull & Run Docker Image
1
2
3
4
5
6
7
docker run -d \
--name deepseek-ocr \
--runtime nvidia \
--gpus all \
-p 8000:8000 \
--ipc=host \
gsantopaolo/deepseek-ocr:latest
Option C: Build From Source
Clone the repo and follow the build instructions for custom deployments.
For complete deployment guides, API usage examples, and production considerations, visit the GitHub repository.
Conclusion
DeepSeek-OCR represents more than an incremental improvement in OCR technology. It’s a proof-of-concept for a fundamental rethinking of how AI systems handle information. By demonstrating that vision tokens can compress text 10-20x while maintaining high accuracy, DeepSeek has opened a path toward:
- Practical 10-20M token context windows
- Elimination of tokenizer complexity
- Vision-first LLM architectures
- New paradigms for AI memory and reasoning
This continues DeepSeek’s pattern of challenging conventional approaches (as seen with DeepSeek-R1) and exploring unconventional solutions. The question isn’t whether this will impact how we build AI systems - it’s how soon and how dramatically.
The future of LLMs might not be about better tokenizers - it might be about eliminating them entirely.
Need Help with Your AI Project?
Whether you’re building a new AI solution or scaling an existing one, I can help. Book a free consultation to discuss your project.