RAG vs. CAG: A New Frontier in Augmenting Language Models
Large language models (LLMs) are undoubtedly powerful—but they come with a catch: a knowledge cutoff. If a fact wasn’t in the training data or if it’s something new (like who won the 2025 Best Picture at the Oscars), the model might struggle. To bridge this gap, augmented generation techniques have emerged, with two main players in the field: Retrieval-Augmented Generation (RAG) and Cache-Augmented Generation (CAG).
In this post, we’ll explore both methods in depth, discuss their inner workings, and highlight scenarios where each might excel.
What Is RAG?
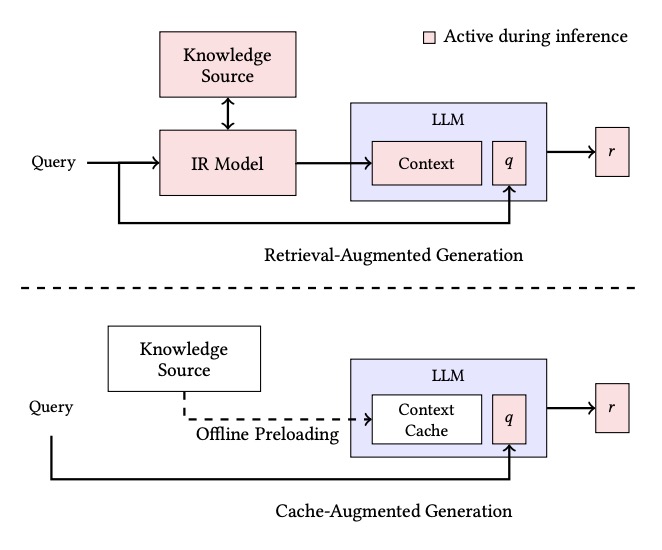
Retrieval-Augmented Generation (RAG) works by dynamically fetching relevant information from an external knowledge base when a query is made. Here’s how it typically works:
Offline Knowledge Ingestion:
Your documents—be it PDFs, Word files, or any other text—are split into chunks and converted into vector embeddings. These embeddings are stored in a searchable vector database.Online Retrieval and Generation:
When a user asks a question, the model transforms the query into an embedding and searches the vector database. It retrieves the top K most relevant chunks and appends them to the original query before passing everything to the LLM. In other words, the LLM generates an answer based on both the question and the freshly retrieved context.
Pros and Cons of RAG
Scalability:
Because only a small, relevant slice of data is retrieved per query, RAG can handle enormous knowledge bases—think millions of documents.Data Freshness & Citation:
The system can easily update its knowledge base. When new information becomes available, you only need to update the embeddings, ensuring the model always has the latest data. Plus, the retrieval mechanism naturally provides citations to source documents.Latency:
The extra step of retrieval introduces some overhead. Every query involves vector computation and a similarity search before the LLM can generate an answer.
What Is CAG?
Cache-Augmented Generation (CAG) takes a very different approach. Instead of retrieving information on demand, CAG preloads the entire knowledge base into the model’s context during an offline phase. Here’s the breakdown:
Preloading the Knowledge Base:
All relevant documents are fed into the LLM in one massive prompt that fits within its extended context window. The model processes this data and computes a key-value (KV) cache—a compact, internal representation of all that information.Instantaneous Inference:
When a user query comes in, the model doesn’t need to perform any retrieval. Instead, it appends the query to the precomputed KV cache and generates an answer based on its “memorized” knowledge.
Pros and Cons of CAG
Latency:
With no need for real-time retrieval, responses are generated faster because the heavy lifting was already done during the preloading phase.Unified Context:
Since the entire knowledge base is available at inference time, the model can answer queries with a holistic view, reducing the risk of missing critical context.Scalability Limitations:
The downside? You’re limited by the model’s context window. If your knowledge base is too large (imagine millions of documents), you simply can’t preload it all.Data Updates:
If the underlying information changes frequently, you’ll need to recompute the cache—something that can be computationally expensive.
RAG vs. CAG: A Practical Comparison
A recent paper titled Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks introduces CAG as a streamlined alternative to RAG for scenarios where the knowledge base is manageable in size. The authors show that by preloading and caching external documents, CAG can often outperform RAG—not only in accuracy (thanks to its unified context) but also in reducing the overall latency caused by real-time retrieval steps.
Let’s break this down:
RAG in Action:
In a typical RAG setup, the process involves two phases—an offline (asynchronous) phase where documents are ingested and an online phase where a retriever fetches the top relevant chunks. This modularity means you can mix and match components like different vector databases, embedding models, or LLMs.CAG in Action:
In contrast, CAG loads “everything” into the context window. Whether it’s Oscar winners or last week’s lunch specials, all the information is pre-cached. When the query comes in, the model uses its precomputed KV cache to generate an answer without the overhead of fetching data.
 Rag vs. CAG
Rag vs. CAG
Use Case Scenarios
Let’s break down a few scenarios to see when you might choose RAG or CAG:
IT Help Desk Bot:
Scenario: A product manual of about 200 pages, updated only a few times a year.
Verdict: CAG shines here—small enough to preload, and the information rarely changes, ensuring lightning-fast responses.Legal Research Assistant:
Scenario: Thousands of legal cases that are frequently updated, with the need for precise citations.
Verdict: RAG is ideal. Its retrieval mechanism supports scalability, dynamic updates, and precise document citations.Clinical Decision Support System:
Scenario: A system that queries patient records, treatment guides, and drug interactions—requiring comprehensive, accurate answers with the ability to handle complex follow-up queries.
Verdict: A hybrid approach might work best. Start with RAG to retrieve the most relevant data, then use CAG to process that information in a long context for deeper reasoning.
Conclusion
Both RAG and CAG offer unique benefits depending on the application:
- RAG is flexible and scalable, making it a strong choice for massive and dynamic knowledge bases.
- CAG simplifies the pipeline and reduces latency, making it ideal when you can preload a fixed set of data into the model’s context.
In an ever-evolving landscape of LLMs and augmented generation, the choice between RAG and CAG ultimately comes down to your specific use case: whether you prioritize real-time updates and scalability or speed and unified context. With innovations continuing on both fronts, the future might well see hybrid systems that combine the best of both worlds.
What’s your take? Would you choose RAG, CAG, or perhaps a hybrid for your next project?
References:
Don’t Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
Need Help with Your AI Project?
Whether you’re building a new AI solution or scaling an existing one, I can help. Book a free consultation to discuss your project.