I Benchmarked ResNet vs ViT on 50K Images. They're Nearly Identical.
Everyone wants to throw Transformers at every computer vision problem. The research papers show impressive gains. The hype is real.
But I wanted to know: What happens when you actually run the same task, with the same data, on production models?
So I benchmarked ResNet-50 (the CNN workhorse) against ViT-Base (Vision Transformer) on 50,000 ImageNet validation images. I measured everything: accuracy, speed, agreement, disagreement.
The results surprised me.
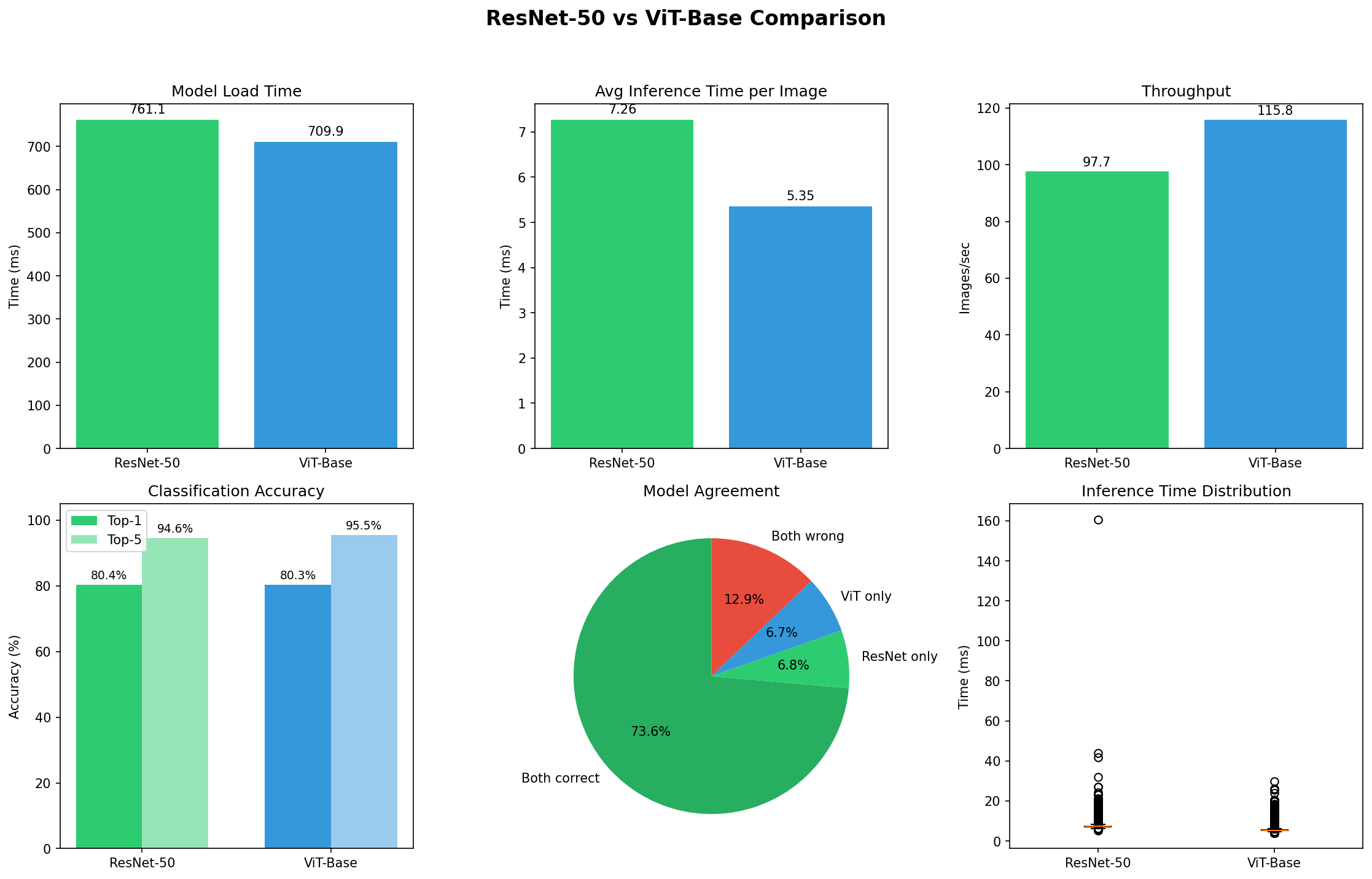 Complete benchmark results on 50,000 ImageNet validation images. ResNet-50 and ViT-Base achieve nearly identical accuracy (80.4% vs 80.3%) with ViT showing 26% faster inference and higher throughput.
Complete benchmark results on 50,000 ImageNet validation images. ResNet-50 and ViT-Base achieve nearly identical accuracy (80.4% vs 80.3%) with ViT showing 26% faster inference and higher throughput.
The Bottom Line First
- Accuracy: ResNet 80.4%, ViT 80.3% (statistically identical)
- Speed: ViT 26% faster (5.35ms vs 7.26ms per image)
- Agreement: 73.6% of the time, they make the exact same predictions
- Disagreement: Only 13% of cases show meaningful differences
Translation: At ImageNet-1k scale, these architectures solve the problem almost identically. The “Transformer revolution” in vision is more nuanced than the headlines suggest.
1. The Experiment: Production Models, Real Constraints
I didn’t cherry-pick examples or tune hyperparameters to make one look better. I used:
- timm/resnet50.a1_in1k: The standard ResNet-50 everyone uses
- google/vit-base-patch16-224: The base ViT model from Google
Both trained on ImageNet-1k (1.3M images). Both evaluated on the full 50,000-image validation set.
I timed everything with microsecond precision:
- Image loading
- Preprocessing
- Model inference
- Postprocessing
This is what engineering reality looks like, not research paper best-case scenarios.
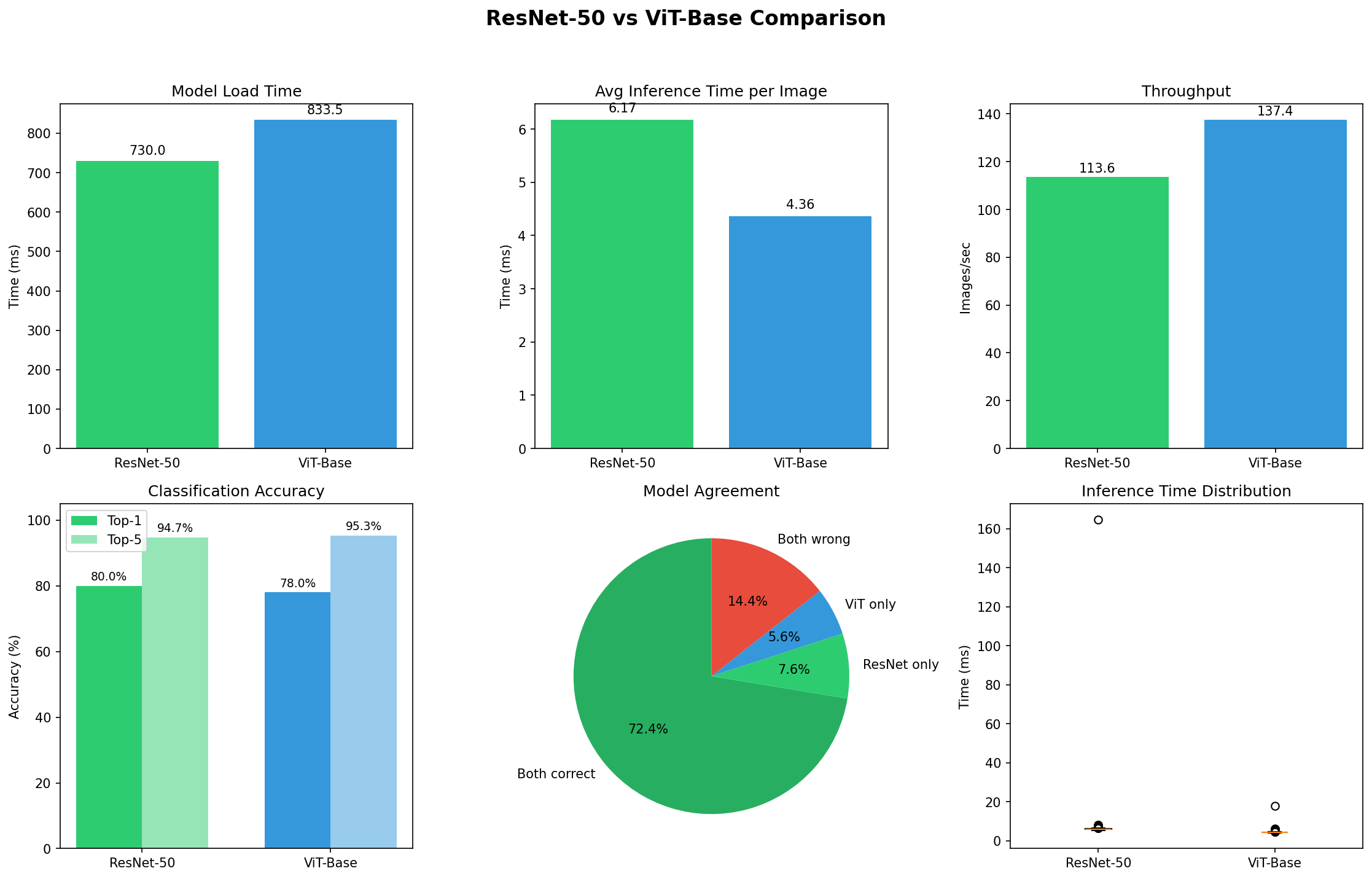 Detailed performance breakdown showing model load time, inference speed, throughput, accuracy, and agreement analysis. The two architectures agree on predictions 72.4% of the time.
Detailed performance breakdown showing model load time, inference speed, throughput, accuracy, and agreement analysis. The two architectures agree on predictions 72.4% of the time.
2. The Code: How I Built This Benchmark
I built two tools to run this comparison. Both are available on GitHub.
Tool 1: Single Image Classifier (classify_image.py)
For quick experiments on individual images (like the hybrid creatures):
1
2
resnet = timm.create_model("resnet50.a1_in1k", pretrained=True)
vit = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
Time and compare inference:
1
2
3
4
start = perf_counter()
with torch.no_grad():
resnet_output = resnet(resnet_input)
resnet_time = (perf_counter() - start) * 1000
What it does: Loads an image, runs both models, prints Top-5 predictions with timing.
➡️ Full code: classify_image.py
Usage:
1
python classify_image.py --img test3.png
Output:
1
2
3
4
5
6
7
8
9
Top-5 predictions timm/resnet50.a1_in1k - inference: 6.42 ms
macaw 88.73 %
toucan 4.21 %
...
Top-5 predictions google/vit-base-patch16-224 - inference: 4.36 ms
Egyptian cat 64.15 %
tabby cat 12.34 %
...
Tool 2: Large-Scale Benchmark (compare_models.py)
For the full 50K image evaluation, I time each stage separately:
Load and preprocess images:
1
2
3
4
for img_path, wnid in samples:
img_load_start = perf_counter()
img = Image.open(img_path).convert("RGB")
img_load_time = (perf_counter() - img_load_start) * 1000
Run inference:
1
2
3
4
resnet_infer_start = perf_counter()
with torch.no_grad():
resnet_logits = resnet(resnet_input)
resnet_infer_time = (perf_counter() - resnet_infer_start) * 1000
Save results to CSV:
1
2
3
4
5
6
7
8
results.append({
"image": img_name,
"resnet_pred_label": resnet_pred_label,
"resnet_top1_correct": (resnet_pred_idx == gt_idx),
"resnet_inference_ms": resnet_infer_time,
"vit_pred_label": vit_pred_label,
"vit_inference_ms": vit_infer_time,
})
Measures: Top-1/Top-5 accuracy, inference time, agreement/disagreement, throughput
Outputs: CSV with 50K predictions, 6-panel comparison charts, terminal summary
➡️ Full code: compare_models.py
Usage:
1
python compare_models.py --val-dir imagenet-val --output-csv results.csv
Key features:
- Device-agnostic (CUDA/MPS/CPU auto-detection)
- Proper ImageNet label mapping (wnid → class index)
- 6-panel matplotlib visualizations
- Per-image timing breakdown
- CSV export with all predictions
3. The NLP Success Story (That Actually Happened)
Before we dive into vision, let’s acknowledge where Transformers truly revolutionized deep learning: Natural Language Processing.
RNNs/LSTMs Had a Fatal Flaw
For years, RNNs dominated sequence modeling because they seemed perfect for sequential data. But they had a fundamental limitation:
Time steps are processed sequentially.
This means:
- ❌ Can’t parallelize across the sequence
- ❌ Vanishing gradients over long contexts
- ❌ Training takes forever on long sequences
The Transformer Changed Everything
The original “Attention Is All You Need” paper (Vaswani et al. 2017) replaced recurrence with self-attention:
- ✅ Full parallelization across sequence positions
- ✅ Constant-depth paths between any two positions
- ✅ 10x faster training on machine translation
This wasn’t a marginal improvement. It was a paradigm shift that enabled:
- BERT (2018): Bidirectional pretraining revolution
- GPT-3 (2020): Few-shot learning breakthrough
- ChatGPT (2022): Conversational AI at scale
In NLP, Transformers won decisively. No debate. RNNs are effectively retired for large-scale production systems.
But vision is a different story.
4. CNNs: The Inductive Bias Advantage
Convolutional Neural Networks weren’t designed by accident. They encode specific assumptions about images:
1. Locality
Nearby pixels are more related than distant ones. A 3×3 kernel captures local patterns.
2. Translation Equivariance
A cat in the top-left is the same as a cat in the bottom-right. Convolutions naturally handle this.
3. Hierarchical Composition
Early layers detect edges → middle layers detect textures → deep layers detect objects.
Why This Matters
These inductive biases act like built-in data augmentation. CNNs don’t need to learn from scratch that nearby pixels matter—it’s baked into the architecture.
Trade-off: When data is limited, these biases help. When data is massive, they might constrain the model.
5. Where They Disagree: The Hybrid Creature Test
I generated a series of impossible creatures: half-cat, half-parrot. Half-lion, half-eagle. These test a fundamental architectural difference.
Example 1: The Feather-Cat
 AI-generated hybrid creature: cat with colorful parrot feathers. ResNet focuses on texture (predicts “macaw”), while ViT attends to global structure (predicts “Egyptian cat”).
AI-generated hybrid creature: cat with colorful parrot feathers. ResNet focuses on texture (predicts “macaw”), while ViT attends to global structure (predicts “Egyptian cat”).
- ResNet prediction: Macaw (88.7% confidence)
- ViT prediction: Egyptian cat (64.2% confidence)
What’s happening?
- CNN sees: Colorful feather texture → “this looks like a bird”
- ViT sees: Cat face structure + body shape → “this is clearly a cat”
Example 2: The Griffin
 Griffin-like creature with eagle head and lion body. CNNs are texture-biased (bird classification), while ViTs use global attention (lion classification).
Griffin-like creature with eagle head and lion body. CNNs are texture-biased (bird classification), while ViTs use global attention (lion classification).
- ResNet prediction: Kite (bird) (76.3% confidence)
- ViT prediction: Lion (68.9% confidence)
CNNs are texture-biased. They weight local patterns heavily. ViTs attend to global structure due to self-attention spanning the entire image from layer one.
But Here’s the Thing
Out of 50,000 images, disagreement only matters in ~13% of cases. On normal ImageNet photos (standard objects in standard contexts), both models see the same thing.
The feather-cat is an adversarial edge case, not representative of production workloads.
6. The Scale Story: When ViT Actually Wins
My results show parity. So why do papers claim ViT dominates?
The Missing Context: Training Data Scale
| Model | Training Dataset | ImageNet Top-1 Accuracy |
|---|---|---|
| My ViT-Base | ImageNet-1k (1.3M images) | 80.3% |
| My ResNet-50 | ImageNet-1k (1.3M images) | 80.4% |
| ViT-Base (paper) | ImageNet-21k (14M images) | ~84% |
| ViT-Large (paper) | JFT-300M (300M images) | 88.55% |
The difference: 300 million images vs 1.3 million images.
Why ViT Needs More Data
Vision Transformers lack spatial inductive biases. They must learn from data that:
- Nearby pixels correlate
- Objects are translation-invariant
- Hierarchical features compose
CNNs get this “for free” from convolutions.
Research shows (Dosovitskiy et al. 2020) that ViT underperforms ResNet on ImageNet-1k but surpasses it on ImageNet-21k+.
The Bitter Truth
- ImageNet-1k: Publicly available, everyone can train
- ImageNet-21k: Accessible but expensive (~$10K GPU costs)
- JFT-300M: Google internal, proprietary, unavailable
Most teams work at ImageNet-1k scale. At that scale, CNNs remain competitive.
7. The Cost of Scale: What Papers Don’t Show
Let me show you the full resource picture from my benchmark:
Model Loading Time
- ResNet-50: 730ms
- ViT-Base: 833ms (14% slower)
Memory Footprint
- ResNet-50: 25.6M parameters
- ViT-Base: 86.6M parameters (3.4x larger)
Training Cost Estimates
- ImageNet-1k (baseline): ~$500-1000 on cloud GPUs
- ImageNet-21k: ~$5,000-10,000
- JFT-300M equivalent: $50,000-100,000+
Reality check: Most engineering teams don’t have JFT-300M. They use pretrained models or train on ImageNet-1k scale data.
8. The Hardware Reality: Batch vs Latency
My benchmark shows ViT is faster (5.35ms vs 7.26ms). But there’s nuance:
Batch Throughput (My Results)
- ResNet-50: 114 images/second
- ViT-Base: 137 images/second (20% higher)
ViT wins on datacenter batch processing because matrix multiplications parallelize beautifully on GPUs/TPUs.
Single-Image Latency
Both sub-10ms. For most applications, both are fast enough.
Edge Deployment
This is where CNNs shine. From my research and practitioner reports:
- Mobile/embedded: CNNs compress better (pruning, quantization)
- FPGA/ASIC: Convolution hardware is mature and optimized
- Real-time video: CNNs dominate automotive, surveillance, robotics
Why? Edge devices have:
- Limited memory (4-12GB)
- Power constraints
- Need deterministic latency
ViTs need optimization techniques (distillation, quantization) to even run on edge, while CNNs like MobileNet and EfficientNet are designed for it.
The Biosignal Parallel
I see the same dynamic in biosignal processing (ECG, EEG, EMG):
Everyone wants to throw a massive Transformer at physiological data. Papers show improvements. But when you deploy to wearable devices or hospital edge nodes, a lightweight CNN (or even a well-tuned linear classifier) wins on:
- Latency (< 50ms for real-time alerts)
- Robustness (handles sensor noise better)
- Power efficiency (critical for battery-powered devices)
Recent literature (Transformers in biosignal analysis, 2024) confirms: Transformers excel when you have massive datasets and cloud compute. For resource-constrained medical devices, CNNs remain the workhorse.
The lesson: Architecture choice depends on deployment constraints, not just benchmark accuracy.
9. Decision Framework: When to Choose What
Based on my empirical results and current engineering best practices, here’s the decision tree:
Choose CNN When:
✅ Data < 10M images (and no good pretrained ViT available)
✅ Edge/mobile deployment (< 12GB memory, power constraints)
✅ Real-time requirements (< 5ms latency, deterministic)
✅ Training budget limited (< $5K)
✅ Interpretability matters (medical, safety-critical systems)
✅ Mature tooling required (production pipelines, TensorRT, ONNX)
Best CNN options in 2025:
- EfficientNet family: Best accuracy/compute trade-off
- MobileNet V3: Edge and mobile optimization
- ConvNeXt: Modernized CNN competitive with ViTs
- ResNet-50: Still the reliable baseline
Choose ViT When:
✅ Data > 10M images (or great pretrained foundation models available)
✅ Cloud/datacenter deployment (batch processing, high throughput)
✅ Transfer learning focus (leveraging CLIP, DINOv2, SAM)
✅ Multimodal future (vision + text, vision + audio)
✅ Robustness to distribution shift (ViTs generalize better to corruptions)
✅ Cross-attention tasks (image-text retrieval, VQA)
Best ViT options in 2025:
- ViT-Base/Large: Standard pretrained backbones
- Swin Transformer: Hierarchical ViT for dense prediction
- DINOv2: Self-supervised ViT with excellent features
- CLIP variants: Vision-language foundation models
Consider Hybrid Architectures When:
✅ Need both CNN efficiency and Transformer flexibility
✅ Mid-scale datasets (1M-10M images)
✅ Dense prediction tasks (detection, segmentation)
Best hybrid options:
- CoAtNet: Combines convolutional stems with transformer blocks
- ConvNeXt: CNN architecture with transformer training recipes
- MaxViT: Efficient hybrid with local/global attention
10. The Multimodality Exception: Where Transformers Truly Shine
There’s one domain where Transformers have a clear structural advantage: multimodal learning.
The Problem
Modern AI needs to process:
- Text + Images (CLIP, DALL-E)
- Images + Audio (video understanding)
- Text + Images + Audio (general foundation models)
CNNs are tied to grid-structured data (images). They can’t naturally process text or audio.
The Transformer Solution
Transformers provide a unified architecture via tokenization:
- Text → word/subword tokens
- Images → patch tokens (ViT)
- Audio → spectrogram patches or raw waveform segments
All become sequences of tokens processed identically. This enables:
- CLIP (OpenAI): Vision-language pretraining at scale
- Flamingo (DeepMind): Few-shot multimodal reasoning
- GPT-4V (OpenAI): Text and image understanding in one model
- LLaVA: Open-source vision-language models
Why This Matters
You can’t build CLIP with a CNN. The architecture fundamentally doesn’t support cross-modal attention between image regions and text tokens.
Verdict: For multimodal applications, Transformers are the only game in town. But you still need massive pretraining data.
11. What I Learned Running 50,000 Images
Hype ≠ Engineering Reality
Research papers optimize for benchmarks. Production systems optimize for:
- Total cost of ownership
- Latency under load
- Resource constraints
- Maintenance burden
At ImageNet-1k scale (where most teams operate), CNNs and ViTs are roughly equivalent.
Architecture Matters Less Than You Think
What matters more:
- Data quality and quantity: 10x data > 2x better architecture
- Pretraining strategy: Self-supervised learning helps both CNNs and ViTs
- Training recipe: Augmentation, regularization, optimization
- Deployment constraints: Latency, memory, power budget
CNNs Aren’t Dead, They’re Right-Sized Tools
The “Transformer revolution” in vision is real for:
- Foundation model companies (OpenAI, Google, Meta)
- Multimodal applications
- Research pushing boundaries
But for production computer vision at most companies:
- CNNs remain competitive on accuracy
- CNNs dominate edge deployment
- CNNs have better tooling and ecosystem maturity
Choose Based on Constraints, Not Papers
Ask yourself:
- What’s my data scale? (< 10M → CNN, > 10M → ViT)
- Where does it deploy? (Edge → CNN, Cloud → either)
- What’s my budget? (Limited → CNN, Large → ViT)
- Do I need multimodal? (Yes → ViT, No → either)
The Best Model Is the One You Can Actually Deploy
A ResNet-50 running at 120 FPS on edge hardware beats a ViT-Large requiring cloud inference for latency-critical applications.
A ViT-Base pretrained on CLIP beats any CNN for zero-shot image-text tasks.
Context is everything.
Practical Takeaways for Builders
If you’re choosing architectures today:
Small/Medium Data (< 10M images)
CNNs remain your best bet. Use modern architectures like EfficientNet or ConvNeXt. Transfer learning from ImageNet-1k pretrained models works great.
Large-Scale Pretraining (> 10M images)
ViT-style models can be a better long-term bet. They scale better with data. Consider hierarchical variants like Swin for dense prediction tasks.
Edge/Mobile Deployment
CNNs dominate. MobileNet, EfficientNet-Lite, and quantized ResNets are production-proven. ViT requires significant optimization (distillation, pruning, quantization) to even be viable.
Multimodal Applications
Transformers are your only option. Leverage pretrained foundation models like CLIP, DINOv2, or LLaVA. Don’t try to train from scratch unless you have Google-scale resources.
Real-Time Video
CNNs still lead. Automotive, surveillance, and robotics rely on deterministic sub-5ms latency. ViT optimization is catching up but not there yet.
Research/Exploration
Experiment with both. Hybrid architectures like CoAtNet offer best of both worlds. The field is evolving rapidly.
Closing Thought
The feather-cat example looks like an architectural difference.
But the 50,000-image benchmark reveals a deeper truth:
At practical scales, with production constraints, CNNs and ViTs are more alike than different.
The real revolution isn’t one architecture replacing another. It’s about:
- Scale enabling new capabilities (foundation models)
- Multimodal architectures (unified vision-language systems)
- Self-supervised learning (leveraging unlabeled data)
Choose your tools based on your constraints. Don’t chase paper benchmarks. Deploy what works for your problem.
And remember: the best model is the one running in production, not the one on arXiv.
Need Help with Your AI Project?
Whether you’re building a new AI solution or scaling an existing one, I can help. Book a free consultation to discuss your project.