Tensor Parallelism in Transformers: A Hands-On Guide for Multi-GPU Inference
Running a 70B parameter model on a single GPU? Not happening. Even the beefiest H100 with 80GB of VRAM can’t hold Llama-2-70B in full precision. This is where Tensor Parallelism (TP) comes in — it splits the model’s weight matrices across multiple GPUs so you can run models that would otherwise be impossible.
This guide is hands-on. We’ll cover the theory just enough to understand what’s happening, then dive straight into code. By the end, you’ll have working scripts for running tensor-parallel inference on RunPod and Lambda Cloud.
Why Tensor Parallelism? The Memory Wall Problem
Modern LLMs are massive. Here’s a quick reality check:
| Model | Parameters | FP16 Memory | FP32 Memory |
|---|---|---|---|
| Llama-3-8B | 8B | ~16 GB | ~32 GB |
| Llama-3-70B | 70B | ~140 GB | ~280 GB |
| Llama-3-405B | 405B | ~810 GB | ~1.6 TB |
A single A100 (80GB) can barely fit Llama-3-70B in FP16 — and that’s before accounting for KV cache, activations, and batch size overhead. For anything larger, you need to split the model across GPUs.
The Parallelism Zoo
There are several ways to distribute work across GPUs:
graph TB
subgraph "Data Parallelism"
DP1[GPU 0: Full Model<br/>Batch 0-7]
DP2[GPU 1: Full Model<br/>Batch 8-15]
DP3[GPU 2: Full Model<br/>Batch 16-23]
end
subgraph "Pipeline Parallelism"
PP1[GPU 0: Layers 0-10]
PP2[GPU 1: Layers 11-20]
PP3[GPU 2: Layers 21-31]
PP1 --> PP2 --> PP3
end
subgraph "Tensor Parallelism"
TP1[GPU 0: Slice of ALL layers]
TP2[GPU 1: Slice of ALL layers]
TP3[GPU 2: Slice of ALL layers]
end
| Strategy | What’s Split | Memory per GPU | Communication |
|---|---|---|---|
| Data Parallelism | Data batches | Full model on each GPU | Gradient sync after backward |
| Pipeline Parallelism | Layers | Subset of layers | Activations between stages |
| Tensor Parallelism | Weight matrices | Slice of every layer | All-reduce within each layer |
When to use Tensor Parallelism:
- Model doesn’t fit on a single GPU
- You have fast interconnects (NVLink, InfiniBand)
- You want to minimize latency for inference
How Tensor Parallelism Works
The core insight is simple: matrix multiplications can be parallelized by splitting the matrices.
Column-Parallel Matrix Multiplication
Suppose you need to compute $Y = XW$ where $X$ is your input and $W$ is a weight matrix. If you split $W$ into column blocks:
\[W = [W_1 \mid W_2 \mid \ldots \mid W_n]\]Then each GPU computes its slice independently:
\[Y_i = X \cdot W_i\]The outputs are naturally sharded by columns — no communication needed yet.
graph LR
subgraph "Input (Replicated)"
X[X<br/>Full Input]
end
subgraph "Weights (Column-Split)"
W1[W₁]
W2[W₂]
W3[W₃]
W4[W₄]
end
subgraph "Output (Column-Sharded)"
Y1[Y₁]
Y2[Y₂]
Y3[Y₃]
Y4[Y₄]
end
X --> W1 --> Y1
X --> W2 --> Y2
X --> W3 --> Y3
X --> W4 --> Y4
Row-Parallel Matrix Multiplication
Now suppose you have column-sharded input $X = [X_1 \mid X_2 \mid \ldots \mid X_n]$ and you split $W$ into matching row blocks:
\[W = \begin{bmatrix} W_1 \\ W_2 \\ \vdots \\ W_n \end{bmatrix}\]Each GPU computes a partial result:
\[Y_i = X_i \cdot W_i\]Then you sum across GPUs (all-reduce) to get the final output:
\[Y = \sum_i Y_i\]graph LR
subgraph "Input (Column-Sharded)"
X1[X₁]
X2[X₂]
X3[X₃]
X4[X₄]
end
subgraph "Weights (Row-Split)"
W1[W₁]
W2[W₂]
W3[W₃]
W4[W₄]
end
subgraph "Partial Outputs"
P1[Y₁ partial]
P2[Y₂ partial]
P3[Y₃ partial]
P4[Y₄ partial]
end
X1 --> W1 --> P1
X2 --> W2 --> P2
X3 --> W3 --> P3
X4 --> W4 --> P4
P1 --> AR[All-Reduce<br/>Sum]
P2 --> AR
P3 --> AR
P4 --> AR
AR --> Y[Y<br/>Final Output]
This is the key operation that requires GPU-to-GPU communication.
TP in Transformer Layers
Now let’s see how these primitives apply to actual Transformer components.
Attention Layer
The attention mechanism has three projection matrices: $W_Q$, $W_K$, $W_V$ (queries, keys, values) and an output projection $W_O$.
Step 1: Split Q, K, V Projections (Column-Parallel)
Each GPU gets a subset of attention heads. If you have 32 heads and 4 GPUs, each GPU handles 8 heads.
1
2
3
4
GPU i computes (column slices of weight matrices):
Q_i = X × W_Q[all_rows, columns_for_heads_i]
K_i = X × W_K[all_rows, columns_for_heads_i]
V_i = X × W_V[all_rows, columns_for_heads_i]
No communication needed — each GPU works independently.
Step 2: Local Attention Computation
Since attention heads are independent, each GPU computes attention for its heads locally:
1
2
GPU i computes attention locally:
attn_i = softmax(Q_i × K_i^T / √d_k) × V_i
Still no communication.
Step 3: Output Projection (Row-Parallel)
The output projection $W_O$ is split by rows. Each GPU multiplies its attention output by its slice of $W_O$, then we all-reduce:
1
2
3
4
5
GPU i computes partial output (row slice of W_O):
partial_i = attn_i × W_O[rows_for_gpu_i, all_cols]
All GPUs synchronize:
output = AllReduce(partial_0 + partial_1 + ... + partial_n)
One all-reduce per attention layer.
Feed-Forward Network (FFN)
The FFN typically has two linear layers with an activation in between:
\[\text{FFN}(x) = \text{GELU}(x W_1) W_2\]First Linear (Column-Parallel):
1
2
GPU i computes:
hidden_i = GELU(x × W1[all_rows, cols_for_gpu_i])
Second Linear (Row-Parallel):
1
2
3
4
5
GPU i computes:
partial_i = hidden_i × W2[rows_for_gpu_i, all_cols]
All GPUs synchronize:
output = AllReduce(sum of all partial_i)
One all-reduce per FFN layer.
The Full Picture
graph TB
subgraph "Transformer Layer with TP"
Input[Input X<br/>Replicated] --> QKV[Q, K, V Projections<br/>Column-Parallel]
QKV --> Attn[Local Attention<br/>Per-GPU Heads]
Attn --> OutProj[Output Projection<br/>Row-Parallel]
OutProj --> AR1[All-Reduce]
AR1 --> LN1[LayerNorm]
LN1 --> FFN1[FFN Linear 1<br/>Column-Parallel]
FFN1 --> Act[GELU]
Act --> FFN2[FFN Linear 2<br/>Row-Parallel]
FFN2 --> AR2[All-Reduce]
AR2 --> LN2[LayerNorm]
LN2 --> Output[Output]
end
style AR1 fill:#f96,stroke:#333,stroke-width:2px
style AR2 fill:#f96,stroke:#333,stroke-width:2px
Total communication per layer: 2 all-reduce operations.
Constraints
TP comes with a few practical constraints:
- TP size ≤ number of attention heads — you can’t split a single head across GPUs
- Heads must be divisible by TP size — each GPU needs an equal share
- FFN hidden dimension must be divisible by TP size
For Llama-3-70B with 64 heads, valid TP sizes are: 1, 2, 4, 8, 16, 32, 64.
Tensor Parallelism with HuggingFace Transformers
The good news: HuggingFace Transformers now has built-in TP support. For supported models, it’s a one-liner.
The 3-Line Solution
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# tp_inference.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
torch_dtype=torch.bfloat16,
tp_plan="auto" # <-- This enables tensor parallelism
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
prompt = "Explain tensor parallelism in one paragraph:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Launching with torchrun
You can’t just run python tp_inference.py. You need to launch it with torchrun to spawn multiple processes:
1
2
# Run on 4 GPUs
torchrun --nproc-per-node 4 tp_inference.py
Each process gets assigned to one GPU, and PyTorch’s distributed runtime handles the communication.
Supported Models
As of late 2025, HuggingFace supports TP for:
- Llama (all versions)
- Mistral
- Mixtral
- Qwen
- Gemma
- And more…
Check the model’s config for _tp_plan to see if it’s supported:
1
2
3
from transformers import AutoConfig
config = AutoConfig.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
print(config._tp_plan) # Shows the default TP plan
Partitioning Strategies
Under the hood, HuggingFace uses these strategies:
| Strategy | Description |
|---|---|
colwise | Column-parallel (for Q, K, V projections) |
rowwise | Row-parallel (for output projections) |
sequence_parallel | For LayerNorm, Dropout |
replicate | Keep full copy on each GPU |
You can define a custom tp_plan if needed:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
tp_plan = {
"model.layers.*.self_attn.q_proj": "colwise",
"model.layers.*.self_attn.k_proj": "colwise",
"model.layers.*.self_attn.v_proj": "colwise",
"model.layers.*.self_attn.o_proj": "rowwise",
"model.layers.*.mlp.gate_proj": "colwise",
"model.layers.*.mlp.up_proj": "colwise",
"model.layers.*.mlp.down_proj": "rowwise",
}
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
torch_dtype=torch.bfloat16,
tp_plan=tp_plan
)
Hands-On: Running TP on RunPod
RunPod offers on-demand GPU pods with multi-GPU configurations. Let’s run Llama-3-70B with tensor parallelism.
Step 1: Spin Up a Multi-GPU Pod
- Go to RunPod → Pods → Deploy
- Select a template with PyTorch (e.g.,
runpod/pytorch:2.1.0-py3.10-cuda11.8.0) - Choose a multi-GPU configuration:
- 4× A100 80GB for Llama-3-70B
- 8× H100 for larger models or faster inference
Critical: Select instances with NVLink interconnect (e.g., SXM variants like A100-SXM or H100-SXM), not PCIe. NVLink provides 600-900 GB/s bandwidth between GPUs, while PCIe is limited to ~64 GB/s. Without NVLink, the all-reduce operations in tensor parallelism become a severe bottleneck, negating most of the performance gains.
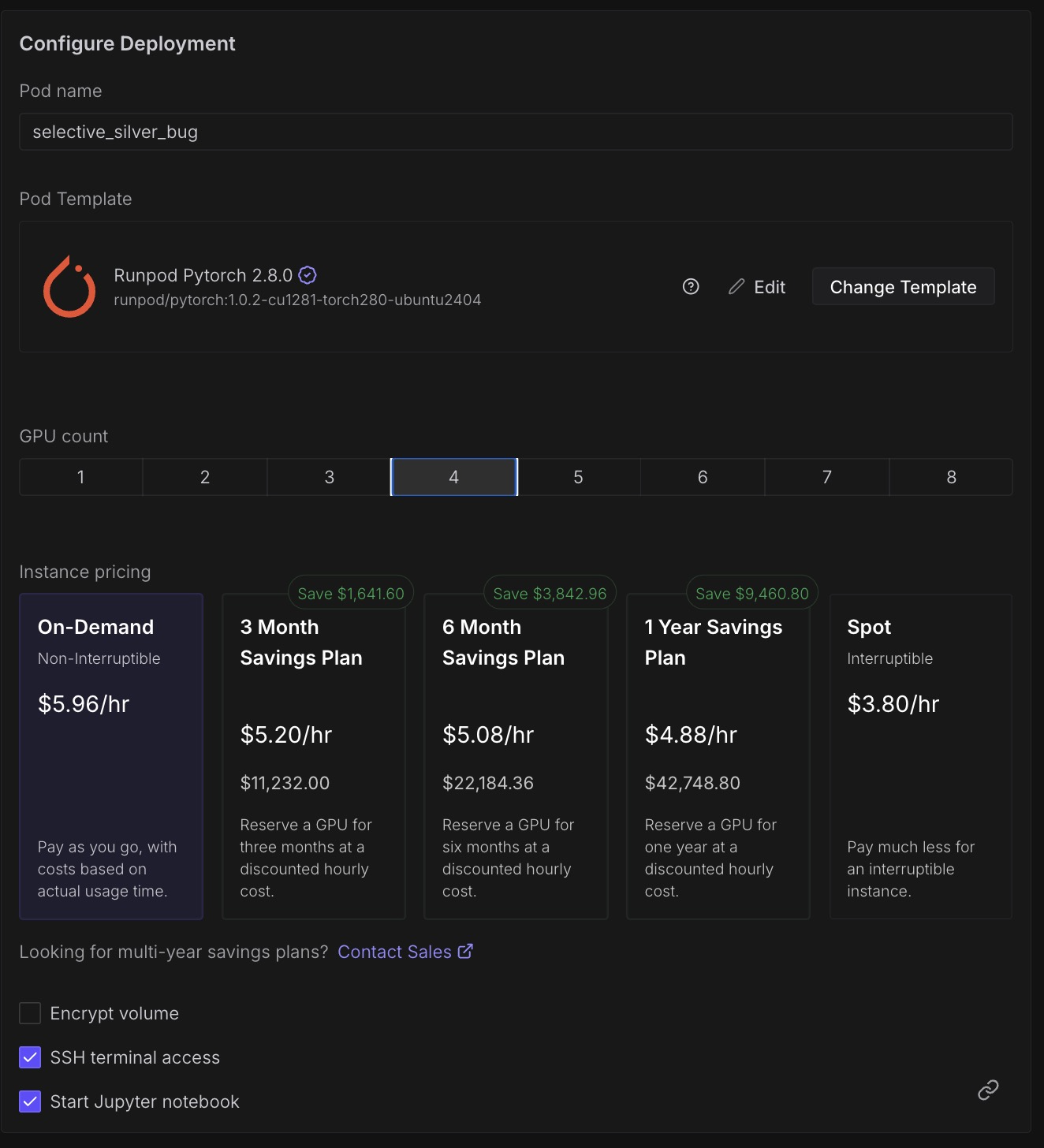 Selecting a 4×A100 pod on RunPod — look for SXM variants with NVLink
Selecting a 4×A100 pod on RunPod — look for SXM variants with NVLink
Step 2: Environment Setup
SSH into your pod and set up the environment:
1
2
3
4
5
6
7
8
# Update and install dependencies
pip install --upgrade transformers accelerate torch
# Verify GPU setup
nvidia-smi
# Check NCCL (the communication backend)
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}'); print(f'GPU count: {torch.cuda.device_count()}')"
Expected output:
1
2
CUDA available: True
GPU count: 4
Step 3: Create the Inference Script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# runpod_tp_inference.py
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def main():
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
# Load model with tensor parallelism
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
tp_plan="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
# Only rank 0 should print
rank = int(os.environ.get("RANK", 0))
prompts = [
"What is tensor parallelism?",
"Explain the difference between data and model parallelism.",
]
for prompt in prompts:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=200,
do_sample=True,
temperature=0.7,
top_p=0.9,
)
if rank == 0:
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"\n{'='*50}")
print(f"Prompt: {prompt}")
print(f"Response: {response}")
print(f"{'='*50}\n")
if __name__ == "__main__":
main()
Step 4: Launch with torchrun
1
2
3
4
5
# Set your HuggingFace token for gated models
export HF_TOKEN="your_token_here"
# Launch on 4 GPUs
torchrun --nproc-per-node 4 runpod_tp_inference.py
Using vLLM with Tensor Parallelism on RunPod
For production inference, vLLM is often faster. RunPod has native vLLM support:
1
2
3
4
5
6
7
8
9
# Install vLLM
pip install vllm
# Run with tensor parallelism
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-70B-Instruct \
--tensor-parallel-size 4 \
--dtype bfloat16 \
--port 8000
Or use RunPod’s serverless vLLM workers which handle TP automatically:
1
2
3
4
5
6
# In your RunPod serverless handler
handler_config = {
"model_name": "meta-llama/Meta-Llama-3-70B-Instruct",
"tensor_parallel_size": 4,
"dtype": "bfloat16",
}
Hands-On: Running TP on Lambda Cloud
Lambda Cloud offers GPU instances with up to 8× H100s. The setup is similar but with some Lambda-specific details.
Step 1: Launch a Multi-GPU Instance
- Go to Lambda Cloud → Instances → Launch
- Select instance type:
- gpu_8x_h100_sxm5 (8× H100 80GB) — best for large models
- gpu_4x_a100_80gb_sxm4 (4× A100 80GB) — good for 70B models
Critical: Always choose SXM variants (e.g.,
sxm4,sxm5) over PCIe. The “SXM” designation indicates GPUs connected via NVLink with 600-900 GB/s inter-GPU bandwidth. PCIe-based instances share bandwidth through the CPU’s PCIe lanes (~64 GB/s), creating a communication bottleneck that cripples tensor parallelism performance.
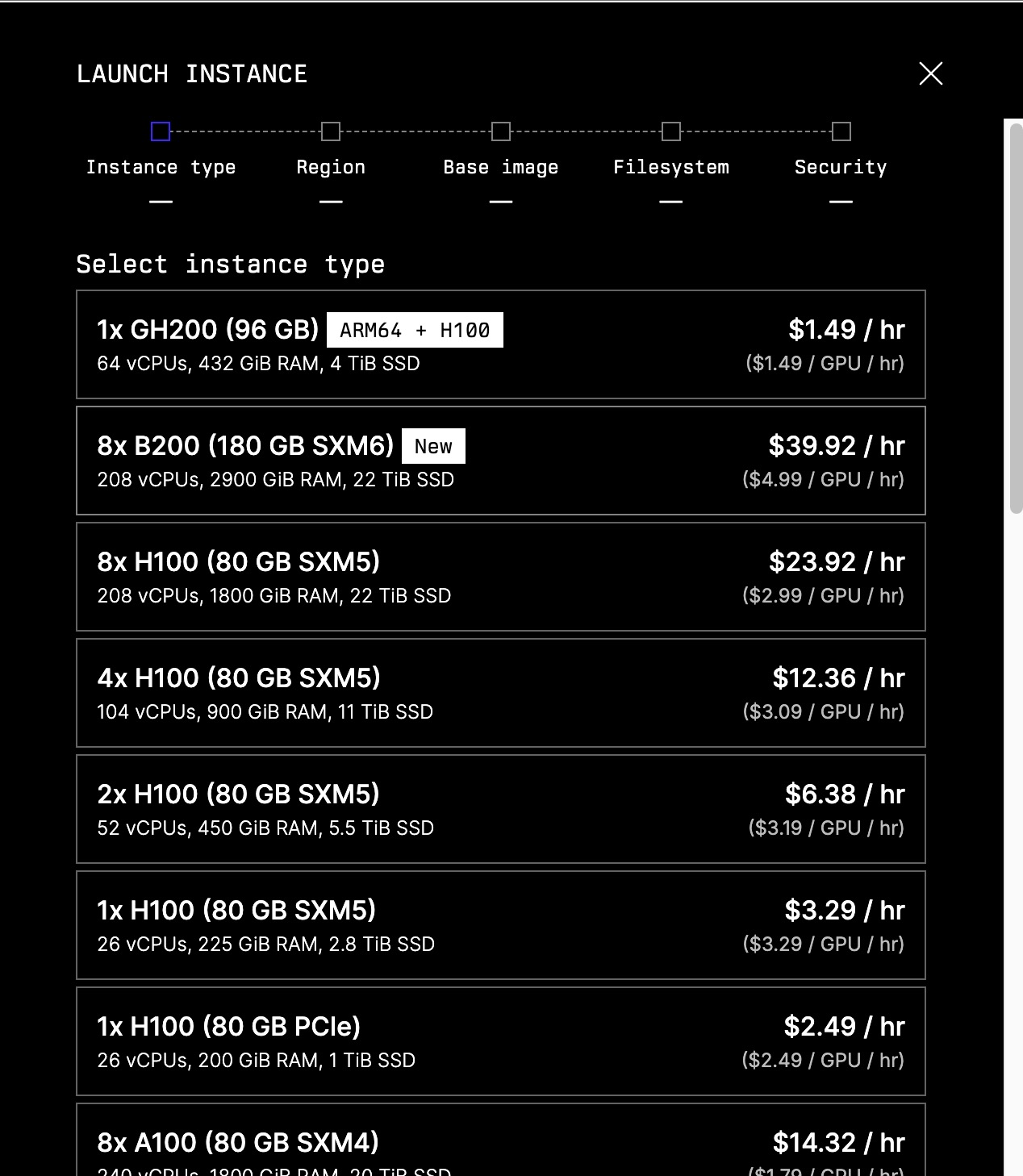 Selecting a multi-GPU instance on Lambda Cloud — SXM variants have NVLink
Selecting a multi-GPU instance on Lambda Cloud — SXM variants have NVLink
Step 2: SSH and Setup
1
2
3
4
5
6
7
8
9
# SSH into your instance
ssh ubuntu@<your-instance-ip>
# Lambda instances come with PyTorch pre-installed
# Just update transformers
pip install --upgrade transformers accelerate
# Verify setup
python -c "import torch; print(f'GPUs: {torch.cuda.device_count()}')"
Step 3: Create the Inference Script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
# lambda_tp_inference.py
import os
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def main():
model_id = "meta-llama/Meta-Llama-3-70B-Instruct"
rank = int(os.environ.get("RANK", 0))
world_size = int(os.environ.get("WORLD_SIZE", 1))
if rank == 0:
print(f"Loading {model_id} with TP across {world_size} GPUs...")
start_time = time.time()
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
tp_plan="auto"
)
if rank == 0:
load_time = time.time() - start_time
print(f"Model loaded in {load_time:.2f}s")
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
# Benchmark inference
prompt = "Write a short poem about distributed computing:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Warmup
with torch.no_grad():
_ = model.generate(**inputs, max_new_tokens=10)
# Timed generation
torch.cuda.synchronize()
start = time.time()
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
do_sample=False, # Greedy for reproducibility
)
torch.cuda.synchronize()
gen_time = time.time() - start
if rank == 0:
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
tokens_generated = outputs.shape[1] - inputs["input_ids"].shape[1]
tokens_per_sec = tokens_generated / gen_time
print(f"\nPrompt: {prompt}")
print(f"Response: {response}")
print(f"\n--- Performance ---")
print(f"Tokens generated: {tokens_generated}")
print(f"Time: {gen_time:.2f}s")
print(f"Throughput: {tokens_per_sec:.1f} tokens/sec")
if __name__ == "__main__":
main()
Step 4: Launch with torchrun
1
2
3
4
5
# For a single node with 4 GPUs
torchrun --nproc-per-node 4 lambda_tp_inference.py
# For 8 GPUs
torchrun --nproc-per-node 8 lambda_tp_inference.py
Multi-Node Setup on Lambda Cloud
If you need more than 8 GPUs, you can run across multiple nodes. Lambda instances support this via torchrun:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# On Node 0 (master)
torchrun \
--nproc-per-node 8 \
--nnodes 2 \
--node-rank 0 \
--master-addr <master-ip> \
--master-port 29500 \
lambda_tp_inference.py
# On Node 1 (worker)
torchrun \
--nproc-per-node 8 \
--nnodes 2 \
--node-rank 1 \
--master-addr <master-ip> \
--master-port 29500 \
lambda_tp_inference.py
This gives you 16 GPUs with tensor parallelism across nodes.
Warning: Cross-node TP requires high-bandwidth interconnects (InfiniBand). Without it, communication overhead can kill performance.
Performance Benchmarks
Here’s what you can expect with tensor parallelism on different configurations:
Llama-3-70B Inference Throughput
| Configuration | TP Size | Tokens/sec | Memory/GPU |
|---|---|---|---|
| 1× H100 80GB | 1 | OOM | — |
| 2× H100 80GB | 2 | ~45 | ~38 GB |
| 4× H100 80GB | 4 | ~85 | ~20 GB |
| 8× H100 80GB | 8 | ~140 | ~12 GB |
Key Observations
- Memory scales linearly — 4× GPUs = ~4× less memory per GPU
- Throughput scales sub-linearly — communication overhead increases with TP size
- Sweet spot is often 4-8 GPUs — beyond that, communication dominates
What TP Doesn’t Solve
Tensor parallelism is powerful, but it has limitations:
1. Scalability is Capped by Attention Heads
If your model has 64 attention heads, TP size can’t exceed 64. In practice, you want TP size much smaller than head count to maintain efficiency.
2. Communication Overhead Across Nodes
TP requires frequent all-reduce operations (2 per layer). Within a node with NVLink (900 GB/s), this is fast. Across nodes with InfiniBand (~400 GB/s) or worse, Ethernet (~100 Gbps), it becomes a bottleneck.
Rule of thumb: Keep TP within a single node. Use Pipeline Parallelism (PP) across nodes.
3. Doesn’t Help with Activation Memory
TP reduces weight memory but not activation memory. For very long sequences, you may still need gradient checkpointing or other techniques.
When to Combine with Pipeline Parallelism
For truly massive models (400B+), combine TP and PP:
1
2
3
4
Node 0: Layers 0-19 (TP=8 within node)
Node 1: Layers 20-39 (TP=8 within node)
Node 2: Layers 40-59 (TP=8 within node)
Node 3: Layers 60-79 (TP=8 within node)
This gives you 32 GPUs total: 8-way TP × 4-way PP.
Practical Takeaways
Decision Tree: Which Parallelism Strategy?
graph TD
A[Model fits on 1 GPU?] -->|Yes| B[Use single GPU]
A -->|No| C[Have fast interconnect<br/>NVLink/InfiniBand?]
C -->|Yes| D[Use Tensor Parallelism<br/>within node]
C -->|No| E[Use Pipeline Parallelism<br/>or model sharding]
D --> F[Need more GPUs<br/>than one node?]
F -->|Yes| G[Combine TP + PP<br/>TP within node, PP across]
F -->|No| H[Done!]
E --> H
G --> H
Quick Reference Commands
1
2
3
4
5
6
7
8
9
10
11
12
13
# HuggingFace Transformers with TP
torchrun --nproc-per-node 4 inference.py
# vLLM with TP
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-70B-Instruct \
--tensor-parallel-size 4
# Check GPU topology (important for TP performance)
nvidia-smi topo -m
# Monitor GPU usage during inference
watch -n 0.5 nvidia-smi
Key Constraints Checklist
Before deploying with TP, verify:
- TP size ≤ number of attention heads
- Attention heads divisible by TP size
- FFN hidden dim divisible by TP size
- All GPUs have NVLink or fast interconnect
- Using
torchrunor equivalent launcher
Wrapping Up
Tensor parallelism is the go-to technique for running models that don’t fit on a single GPU. The key ideas:
- Split weight matrices across GPUs (column-wise for projections, row-wise for outputs)
- All-reduce to aggregate partial results (2× per transformer layer)
- Keep TP within a node for best performance
- Use
tp_plan="auto"in HuggingFace for the easy path
For production inference, consider vLLM which has highly optimized TP implementations. For training, look into FSDP (Fully Sharded Data Parallel) which combines aspects of TP and data parallelism.
References
- HuggingFace Distributed Inference Documentation
- Megatron-LM: Training Multi-Billion Parameter Language Models
- RunPod Multi-GPU Training Guide
- Lambda Labs Multi-Node PyTorch Guide
- vLLM Documentation
- PyTorch Distributed Overview
Need Help with Your AI Project?
Whether you’re building a new AI solution or scaling an existing one, I can help. Book a free consultation to discuss your project.